Import produktów do sklepu: CSV, XML, ERP/PIM — jak zrobić to dobrze i bez błędów
Autor
Digital Vantage TeamData publikacji
Czas czytania

Udostępnij:
Co w artykule?
Pokażę, kiedy zwykły plik raz dziennie „wystarczy”, a kiedy — przy większym katalogu i częstych zmianach — rozsądniej (a prawdopodobnie taniej w dłuższym czasie) przejść na XML z deltą albo API. Po drodze porządkujemy model danych: rozdzielamy product_id, SKU i variant_id, trzymamy w ryzach netto/brutto z VAT-em i pilnujemy, by „available” nie kłóciło się z „reserved”. Na konkretnych przykładach mapujemy pola z feedu do sklepu, normalizujemy jednostki (g/mm → kg/cm), a słowniki kategorii i kolorów przestają być loterią. Zanim cokolwiek wpuścisz do katalogu, włączamy walidacje: twarde odrzucają bzdury (brak SKU, VAT z kosmosu), miękkie tylko ostrzegają (brak zdjęcia), a checksumy trzymają w ryzach duplikaty. Ustalamy rytm pracy: pełny import w nocy, w dzień tylko różnice; bezpieczna kolejność i szybkie „cofnięcie ostatniej partii”, jeśli coś się rozjedzie. Wyjaśniam też, co powinno żyć w ERP (ceny, VAT), co w PIM (opisy, media, tłumaczenia), a sklepowi zostawiamy prezentację — nic na siłę. Do tego praktyka pracy z mediami (nazwy plików, wagi, CDN) i prosty monitoring po imporcie, który wyłapuje rozjazdy stanów i cen, zanim zrobią to klienci. Na koniec — typowe wpadki, szybkie remedia i krótki plan 30/60/90, żeby katalog wreszcie przestał „żyć własnym życiem”.
Wstęp — dlaczego katalog „żyje własnym życiem”?
Masz świeże zdjęcia, nowe ceny, a na karcie produktu… stary opis i brak wariantu „M”? Brzmi znajomo. W e-commerce takie „drobiazgi” potrafią zjeść marżę szybciej niż rabat -10%. Zwykle nie chodzi o „zły system”, tylko o to, jak dane wpadają do sklepu: raz CSV od dostawcy, raz XML z hurtowni, a czasem eksport z ERP „z palca”. Gdy te światy nie mówią jednym językiem, zaczyna się klasyka: duplikaty SKU, znikające zdjęcia, rozjechane ceny.
Niedawno rozmawiałem z właścicielem średniego sklepu DIY. „Wgrywamy feed o 9:00, a o 11:00 i tak poprawiamy ręcznie” — przyznał bez owijania. Krótki audyt i wyszło szydło z worka: XML podmieniał ceny brutto na netto, a CSV nadpisywał opisy pustymi wartościami. Nie wymienialiśmy platformy. Ułożyliśmy kontrakt danych, dorzuciliśmy walidacje i prosty harmonogram: pełny import w nocy, w dzień tylko delta. Efekt? Mniej telefonów do biura, szybciej publikowane nowości i zero „znikających” wariantów. Niby proste — ale dopiero w tej kolejności zaczęło działać.
W tym tekście przeprowadzę Cię przez praktyczny start: jak wybrać ścieżkę importu (CSV/XML/API), co ustawić w mapowaniu pól i jak sprawdzić, czy to rzeczywiście obcina liczbę błędów. Bez żargonu, bez rewolucji.
Zanim włączysz import — 3 pytania, które zdejmą Ci kamień z serca
1) Jaki KPI ma się poprawić?
Zanim klikniesz „Importuj”, nazwij jedną rzecz, którą chcesz zmienić. Jedną, nie pięć.
- Czas publikacji: z „2 dni” do „1 dnia” dla nowej kolekcji.
- % błędów cenowych: z 1,2% do <0,3% po każdej aktualizacji.
- Duplikaty SKU: z „kilkadziesiąt miesięcznie” do zera.
Zapisz cel w formacie „z → do → do kiedy”. Potem projektujesz pod ten cel: walidacje, kolejność, alerty. Inaczej łatwo „upiększyć” proces, który w liczbach dalej kuleje.
2) Gdzie jest „źródło prawdy”?
Dwa źródła prawdy = brak prawdy. Ustal role i się ich trzymaj.
- ERP — ceny, VAT, indeksy, faktury.
- PIM — opisy, atrybuty, zdjęcia, tłumaczenia.
- Sklep — prezentacja i przyjmowanie zamówień.
Jeśli dziś część cen edytujesz w panelu sklepu, a część w ERP, prosisz się o nocne poprawki. Wybierz właściciela danych i zablokuj edycję w pozostałych miejscach (albo przynajmniej ustaw je jako „tylko podgląd”).
3) Jak identyfikujesz produkt i wariant?
Brzmi banalnie, a to tutaj rodzą się katalogowe duchy.
- product_id — stałe, globalne ID (nie zmienia się między feedami).
- sku — unikalny na poziomie wariantu.
- variant_id — identyfikator wariantu (rozmiar/kolor), nie „opis w nawiasie”.
- EAN/Barcode — jeśli jest, świetnie; ratuje integracje i marketplace’y.
U jednego klienta SKU było wspólne dla produktu i wariantu. Przy imporcie delty system „grzecznie” dopisywał warianty jako nowe produkty. Rozdzieliliśmy product_id i variant_id — duplikaty zniknęły. Bez linijki kodu.
Szybki test na dziś: weź 20 losowych SKU i sprawdź, czy we wszystkich plikach (CSV/XML/API) są te same identyfikatory i jednostki (kg vs g, cm vs mm). Jeśli nie — prawdopodobnie właśnie tu uciekają godziny zespołu.
CSV, XML czy API? — szybka mapa decyzji
CSV (ręczny / cykliczny)
Dobry na start i jednorazowe migracje. Prosty, przewidywalny, ale „płaski” — warianty potrafią się tu rozjechać. Sprawdza się przy małych feedach (do ~2–3 tys. SKU) i aktualizacjach raz dziennie. Jeżeli obrabiasz w Excelu, wymuś formaty kolumn (cena jako liczba z kropką, nie przecinkiem).
XML (feed dostawcy)
Lepszy dla hierarchii, drzew atrybutów i wariantów. Zwykle działa w harmonogramie (co X minut/godzin). Bywa „sztywny”, ale daje mniej niespodzianek w złożonych kategoriach. Dobrze znosi deltę (wysyłasz tylko zmienione pozycje).
API (ERP/PIM ↔ Sklep)
Najwięcej kontroli i walidacji, near real-time. Wymaga spisanego kontraktu danych (pola, typy, retry). Sprawdza się, gdy zmiany są częste (promocje godzinowe, dynamiczne stany) i rośnie wolumen.
Tip: jeżeli importujesz >1 raz dziennie i masz >5k SKU, sensownie będzie przejść na API albo XML + delta. CSV zaczyna wtedy „pękać” i łatwo o duplikaty.
Model danych produktu — co naprawdę musi się zgadzać
Identyfikatory i warianty
- product_id — stałe ID produktu.
- sku — unikalny kod wariantu.
- variant_id — identyfikator wariantu (np. rozmiar/kolor).
- barcode/EAN — mile widziany.
Relacja: produkt ma N wariantów; wariant dziedziczy cechy produktu (np. marka), ale ma swoje atrybuty (rozmiar, kolor).
Kontrola jakości: czy jeden SKU wskazuje na dwa warianty w różnych plikach? Jeśli tak — masz generator duplikatów.
Ceny i podatki
- price_net / price_gross — trzymaj oba, albo jedno + vat_rate (jasno opisane).
- currency — ISO 4217 (PLN, EUR), bez „zł” w polu ceny.
- vat_rate — np.
23.00. - Poziomy cen/B2B —
price_tier_1/2/3lub osobna tabela.
Zasada właściciela: jeżeli ceny żyją w ERP, sklep nie powinien ich „korygować”.
Stany i dostępność
- stock_available — sztuki gotowe do sprzedaży.
- reserved — rezerwacje (żeby nie sprzedać dwa razy).
- lead_time — „3–5 dni” itp.
- backorder_policy —
deny/allow/allow_with_date.
SLA odświeżania: stany co 5–10 min (albo eventem); reszta może wolniej.
Treści i SEO
- name — bez upychania fraz.
- slug — unikalny, małe litery, myślniki.
- short_description / long_description — przewidywalny HTML (whitelist tagów).
- meta_title / meta_description — generowane w jednym miejscu (PIM albo sklep).
- filterable_attributes — jawnie (materiał, rozmiar, kolor), nie tylko „w opisie”.
Media
- main_image + gallery[] — pełne URL-e/CDN.
- naming —
sku-variant-01.jpgzamiastIMG_1234.JPG. - wagi/rozmiary — miniatury docelowo < 300–500 KB; oryginały trzymaj osobno.
- video/360 — link do pliku lub osadzenia (upewnij się, że feed nie „tnie” pól).
i18n (wielojęzyczność)
- languages — kody ISO (PL/EN), nie „polski/angielski”.
- fallback — co gdy brak tłumaczenia (np. EN → PL).
- właściciel treści — najczęściej PIM; sklep tylko wyświetla.
- SEO per język — osobny slug/meta dla PL i EN.
Anegdota z wdrożenia: brak fallbacku sprawił, że angielska wersja ściągnęła polskie opisy kategorii. Niby drobiazg, a CTR w UK poleciał o połowę. Jedna flaga „fallback: en→pl” i temat zniknął.
Mapowanie pól — od feedu do sklepu
Tabela mapowania (przykład)
Źródło (feed) | Pole w sklepie | Transformacja / przykład |
|---|---|---|
|
| Bez zmian ( |
|
| Uppercase, trim ( |
|
| Mapuj tylko, gdy |
|
| Wg języka, fallback EN→PL |
|
| Whitelist tagów ( |
|
|
|
|
| ISO 4217 ( |
|
|
|
|
| Słownik marek (unikalne ID/alias) |
|
| Normalizacja wartości (patrz niżej) |
|
| Waliduj URL/rozszerzenie |
|
| Do 10 pozycji, duplikaty out |
|
| Mapa kategorie dostawcy → kategorie sklepu |
|
| Tylko cyfry, długość 8/13 |
|
|
|
Normy typów i jednostek
- Masa: g jako liczba całkowita (np. 750), a nie „0,75 kg”.
- Wymiary: mm (dł./szer./wys.), trzymaj kolejność i typ
int. - Cena: decimal(10,2) z kropką jako separatorem.
- Daty: ISO 8601 w UTC (np.
2025-11-03T12:00:00Z).
Słowniki i normalizacja
- Kategorie: utrzymuj mapę
external_id → internal_id. Dodawaj testy regresji przy każdej zmianie. - Atrybuty: słowniki wartości, np.
color:{"black": "czarny", "jet black": "czarny", "nero": "czarny"}. - Domyślne wartości: jeśli brak
vat_rate→ zastosuj stawkę domyślną z ERP dla danej kategorii.
Reguły uzupełnień (przykłady)
slugpusty? Wygeneruj zname+-sku.- Brak
main_image? Ustaw placeholder + oznacz do uzupełnienia w raporcie. brandnieznana? Mapuj nainnytymczasowo, ale loguj do poprawki.
Walidacje i czyszczenie — błędy, które wyłapujesz przed importem
Walidacje twarde (odrzuć i raportuj)
- Brak
skulubproduct_id. price_gross < 0albovat_ratespoza listy (np. 0/5/8/23).- Nieprawidłowy
barcode(długość/znaki). stock_available < 0po wyliczeniu zestock - reserved.- Rozszerzenia obrazów inne niż
jpg/jpeg/png/webp.
Walidacje miękkie (wpuść z ostrzeżeniem)
- Brak
main_image. - Puste
meta_title/description. - Brak atrybutu filtrowalnego (np.
color). - Zbyt długi
name(>120 znaków) — skróć i zloguj.
Dedup i idempotencja
- Klucz idempotencji:
product_idlub(sku, variant_id). - Wykrywaj duplikaty treści po checksumie (np. SHA-256 z
name+desc+price). - Jeśli przychodzi identyczny rekord — pomijaj (oznacz jako „no-op”).
Jakość SEO (szybkie reguły)
meta_title40–60 znaków;meta_description120–155.slugunikalny w obrębie języka; jeśli konflikt — dodaj-sku.altdomain_image: zbrand + name + wariant.
Czyszczenie treści
- Usuwaj podwójne spacje, niewidoczne znaki, złe encje HTML.
- Whitelist tagów w opisach (
<p><ul><ol><li><strong><em><br>).
Harmonogram i tryby importu
Full vs. delta
- Full (noc/niski ruch): nowa kategoria, duże migracje, rekonstrukcja indeksów.
- Delta (co 15–60 min): zmiany cen, stany, dopisywanie galerii.
- Heurystyka: jeśli >10% rekordów zmienionych — rozważ partiami lub full z oknem serwisowym.
Kolejność importu (bezpieczna)
- Kategorie i słowniki →
- Produkty (rdzeń) →
- Warianty →
- Media (async/CDN, z retry) →
- Stany i ceny (na końcu, jak „klamra” spójności).
Okna ciszy
- Nie wypychaj masowych zmian 18:00–22:00 (szczyt zakupów) i w trakcie akcji promocyjnych.
- Zaplanuj „slot techniczny” (np. 02:00–04:00) na ciężkie joby i reindeks.
Rollback
- Rób snapshot przed każdym dużym batchem (lista
product_id+ kopie pól krytycznych). - Umożliw „cofnięcie ostatniej partii” (flagą publikacji lub przywróceniem z kopii).
- Loguj diff: które pola zmieniono (stare → nowe), kto uruchomił proces, kiedy.
Dobre praktyki operacyjne
- Dry-run: przelot 100 rekordów na stagingu z pełnym raportem walidacji.
- Rate limit i retry z backoffem do CDN/ERP.
- Alert, jeśli
error_rate > 2%w partii albo media mają>10%braków.
ERP vs. PIM — co gdzie trzymać (i po co)
ERP: ceny, stawki VAT, indeksy/kody, dokumenty (faktury, korekty), czasem stany (jeśli ERP jest właścicielem magazynu). Tu liczy się rozliczalność i zgodność — pola „twarde”, audytowalne.
PIM: opisy (krótki/długi), atrybuty filtrowalne, media (foto, video, 360°), tłumaczenia, bundle/kompletacje, reguły prezentacji. PIM to redakcja i spójność wielokanałowa, z wersjami i workflow.
Sklep: prezentacja + koszyk/checkout. Sklep nie powinien „wymyślać” cen ani trzymać długich opisów jako źródła prawdy — pobiera z ERP/PIM i cache’uje.
Dwa scenariusze, które widzę najczęściej:
- „ERP bez PIM” (minimum): mały katalog (do 2–3 tys. SKU), 1–2 języki, proste atrybuty. Treści powstają w sklepie; ryzyko: rozjazdy i brak wersjonowania.
- „PIM jako warstwa treści” (skalowalne): rosną warianty, języki i kanały (marketplace, B2B). ERP trzyma ceny/VAT, PIM całą narrację o produkcie, sklep wyświetla.
Z praktyki: jeśli opisy edytujesz w trzech miejscach, a zdjęcia „giną” przy migracjach, PIM prawdopodobnie spłaci się już przy pierwszej większej aktualizacji.
Pliki i media — praktyka zamiast teorii
Naming, który działa:{sku}-{angle}-{size}.jpg (np. A123-front-1200.jpg). Kąty: front/back/side/detail. Rozszerzenia: WebP preferowany; fallback JPEG. Wideo: MP4/WEBM.
CDN i wagi:
Celuj w ≤300–500 KB na zdjęcie listingu, ≤1–1,5 MB na duże detale. Włącz automatyczny resize/thumbnail (np. ?w=600, ?w=1200 2x). Dodaj lazy loading i srcset, żeby nie przepalać transferu.
Porządek w galeriach:
- Maks. 10 zdjęć/variant (pierwsze 4 „najsprzedajniejsze” kąty).
altgenerowany zbrand + name + wariant.- Zakaz duplikatów (hash pliku do wykrywania kopii).
Kontrola braków:
- Placeholder dla brakującego
main_image. - Cotygodniowy raport „missing assets” (lista SKU bez zdjęć/alt/video).
- Blokada publikacji produktu bez
main_image(miękka: ostrzeżenie na stagingu; twarda: stop na produkcję).
Monitoring i raporty „po imporcie”
Dashboard operacyjny (na jednym ekranie):
- Liczba przetworzonych rekordów / partia.
- % błędów (twarde vs. miękkie) + top przyczyny (brak SKU, zły VAT, media 404).
- Czas importu i średni czas/1000 rekordów (czy nie zwalniamy).
- Rozjazd stanów/cen: ile pozycji różni się między ERP/PIM a sklepem.
Alerty, które mają sens:
- Skok odrzuceń > 2–3× mediany z 7 dni.
- Różnice cen > X% lub > Y zł dla >N SKU w jednej partii.
- Brak zdjęć > Y SKU po imporcie (np. >50).
- Timeout do CDN/ERP powyżej progu (np. >5% żądań w 10 min).
Log zmian (kto/co/kiedy):
- Identyfikator batcha + użytkownik/automat, który go uruchomił.
- Link do źródłowego pliku/endpointu (wersja, checksum).
- Diff pól krytycznych (stare → nowe): cena, dostępność, kategoria, status publikacji.
- Flaga „rollbackable” + odnośnik do snapshota.
Mała uwaga z praktyki: jeśli po imporcie nie widzisz od razu rozjazdów stanów/cen, to znaczy, że będziesz je łapać na… zgłoszeniach klientów. Dashboard i alerty kosztują mniej niż weekend poprawiania „znikających” cen.
Najczęstsze błędy i jak ich uniknąć
Jeden SKU w kilku produktach → duplikaty.
Rozdziel ID produktu (np. prod_123) od ID wariantu (np. prod_123-red-42). SKU ma być unikalne na poziomie wariantu. Masz dziś wspólne SKU? Zacznij od słownika wariantów i migracji na stagingu.
Mieszanie netto/brutto/VAT → chaos cenowy.
Ustal model: albo przechowujesz netto + VAT i liczysz brutto w sklepie, albo brutto jako źródło prawdy. Konsekwentnie. Trzymaj w feedzie price_net, vat_rate, wyliczaj price_gross + currency.
Nadpisywanie treści „pustym” feedem → wyzerowane opisy.
Zamiast „pełnego młota” użyj delty i reguł scalania: jeśli description w pliku jest puste → nie nadpisuj. To drobiazg, który ratuje weekend.
Import w godzinach szczytu → spadek wydajności i UX.
Trzymaj się okien: full w nocy, delty co 15–60 min. Gdy musisz „w dzień”, porcjuj po 500–1000 rekordów i obserwuj TTFB.
Brak stagingu i smoke-testu (20 SKU) przed runem.
Zawsze zaczynaj od mini-próby: 20 reprezentatywnych SKU (kategorie, warianty, ceny). Sprawdź ceny, VAT, zdjęcia, filtrowanie, meta. Dopiero potem „pełna para”.
ROI i TCO — czy to się opłaca?
Koszty (TCO).
Licencje (importer/PIM/CDN), utrzymanie i monitoring, roboczogodziny zespołu (mapowanie, walidacje, poprawki), a do tego migracje i staging. Bywa przewrotnie: „tani” CSV wychodzi najdrożej, bo płacisz czasem ludzi za ręczne gaszenie błędów i poprawki po nocach.
Zyski (ROI).
Mniej duplikatów i pomyłek cenowych, szybsza publikacja kolekcji, mniej ticketów w stylu „zły opis/zdjęcie”, niższy overselling, a marketing wreszcie dostaje kompletne atrybuty i media. Niby przyziemne, ale zwykle skraca time-to-market z dni do godzin — i to czuć w sprzedaży.
Policz to bez magii:
oszczędność_mies = (minuty_poprawki_przed – minuty_po) × liczba_zmian_mies × stawkaROI_mies = oszczędność_mies – (licencje + utrzymanie)
Jeśli payback nie mieści się w 3–4 miesiącach przy katalogu „w ruchu”, coś się prawdopodobnie rozjeżdża — zwykle w mapowaniu pól albo w walidacjach. Warto wtedy wrócić do podstaw i doszlifować kontrakt danych.
Mini-case
Sklep DIY (~8 000 SKU, dwóch dostawców) tonął w CSV: duplikaty wariantów, zera w wadze, braki zdjęć. Przestawiliśmy proces na XML delta z walidacjami: twarde (brak SKU, błędny VAT, waga=0) i miękkie (mniej niż 2 zdjęcia = ostrzeżenie). Dołożyliśmy staging + rollback batcha i reguły scalania opisów, żeby „pusty” feed nie wyczyścił treści. Po miesiącu: –70% duplikatów, –50% błędów cenowych, a nowa kolekcja wchodziła w 1 dzień (wcześniej 3–4). Brzmi zwyczajnie, ale to właśnie ta zwyczajność robi wynik.
Checklista 30/60/90
30 dni – fundament bez niespodzianek
- Ustal model danych (ID/sku/variant, ceny netto/brutto+VAT, stany, media).
- Zrób mapowanie pól: feed → sklep (z typami i jednostkami).
- Uruchom staging i odpal smoke test na 20 SKU (różne kategorie/warianty).
- W nocy zrób pełny import (full) i sprawdź: ceny, VAT, media, filtry, SEO meta.
60 dni – stabilna delta i jakość danych
- Włącz delta-import co 30–60 min (tylko zmienione rekordy).
- Dodaj walidacje twarde (brak SKU, ujemna cena, VAT) i miękkie (brak zdjęcia/alt, zbyt krótki opis).
- Skonfiguruj alerty: skok odrzuceń, różnice cen >X%, brak zdjęć >Y SKU.
90 dni – wygoda i skala
- Rozważ PIM jako warstwę treści (opisy, atrybuty, media, tłumaczenia).
- Wprowadź raport jakości SEO (title/desc długość, unikalność slug, alt).
- Dodaj rollback na 1 klik (snapshot ostatniego batcha + cofnięcie zmian).
Chcesz, przelecimy Twoje feedy i mapowanie w 60 minut
— wrócisz z krótką checklistą, listą alertów/ walidacji i wzorem „kontraktu importu” dopasowanym do Twojego ERP/PIM.
Startujesz lub skalujesz e-commerce?
Szukasz prostego planu na uruchomienie lub uporządkowanie e-commerce? Ta seria prowadzi Cię krok po kroku: od wyboru platformy i policzenia kosztów (TCO), przez płatności i logistykę, po operacje (automaty, KPI, integracje) oraz SEO i UX-UI, które realnie podnoszą sprzedaż. Krótkie checklisty, przykłady z MŚP i układ 30/60/90 dni pomagają zacząć dziś i rosnąć bez chaosu.
Zobacz całą serię → Start e-commerce: od fundamentów do pierwszych klientów
Operacje
Procesy, dane i narzędzia, które dają porządek w codziennej pracy (ERP/WMS/CRM), automatyzacje z realnym ROI oraz metryki właściciela (GMV, AOV, LTV).
- Automatyzacja, która daje ROI
Jak wybrać automaty “blisko pieniędzy” (etykiety, tracking, faktury), policzyć payback i nie wpaść w wtyczkozę. - Bezpieczeństwo i RODO w e-commerce
Minimum prawne i techniczne: role, logi dostępu, polityki, kopie i test odtwarzania – bez żargonu. - Import produktów: CSV/ERP bez bólu
Mapping pól, warianty, walidacje i harmonogramy — jak nie rozjechać katalogu i cen. - Integracje ERP/WMS/CRM — porządek w danych
Źródła prawdy, kolejność wdrożeń i monitoring, żeby systemy grały do jednej bramki. - KPI w e-commerce: GMV, AOV, LTV i spółka
Zestaw metryk właściciela sklepu + progi zdrowia i szybkie pulpity. - Obsługa klienta na autopilocie
Boty, szablony, SLA i self-service — mniej ticketów, więcej zadowolonych klientów.
Inne huby informacji
- Platformy
Wybór technologii to decyzja o czasie, elastyczności i kosztach. Tu porównasz opcje (SaaS, open-source, pół-headless/headless), policzysz TCO i zaplanujesz migrację bez utraty SEO. - Płatności i logistyka
Kasa, checkout i dostawy, które nie blokują sprzedaży. Miks metod płatności, taryfy kurierów/3PL, zwroty i marketplace’y — z naciskiem na koszty i UX w PL/UE. - SEO
Ruch, który ma wartość. Techniczne podstawy, architektura informacji i treści, które rosną w Google i wspierają sprzedaż. - UX & UI
Konwersja i doświadczenie kupującego. Formularze, wydajność frontu, wyszukiwarka i micro-copy, które podnoszą CR.

Jak automatyzować sklep, by się zwracało: etykiety, tracking, KPI, e-maile i fulfillment. Prosty model ROI, przykłady i lista szybkich wygranych.

Prosty plan dla MŚP. 2FA, backup z testem, role, CMP, polityki i 1-stronicowy runbook. Zmniejsz ryzyko bez blokowania sprzedaży.
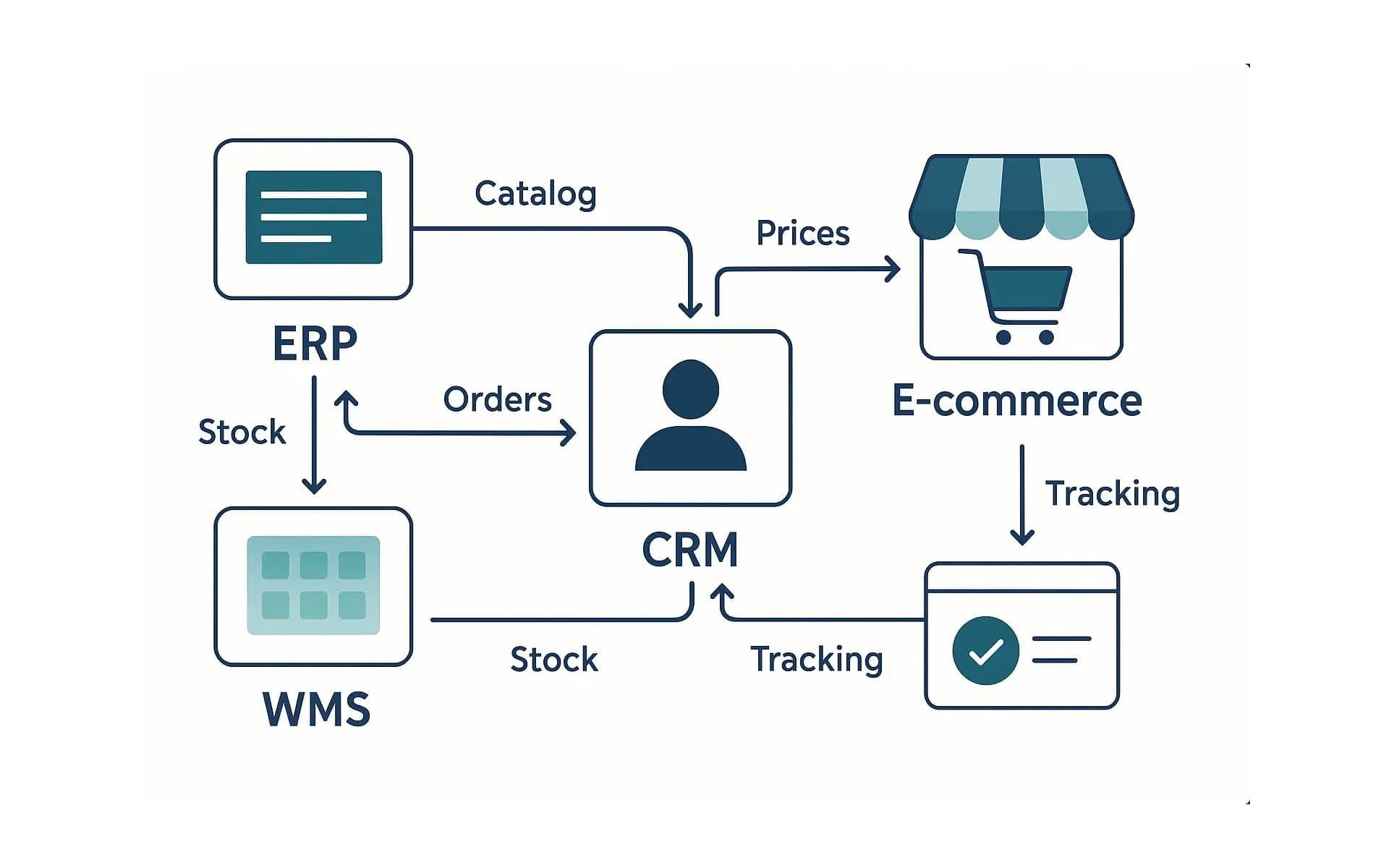
Jak połączyć ERP, WMS, CRM i sklep bez chaosu: źródła prawdy, kolejność wdrożeń, kontrakt danych, monitoring i ROI — praktycznie, w liczbach.
Jak liczyć GMV, AOV, CAC, LTV i marżę, łączyć dane sklep/ERP/GA4 i zbudować dashboard, który chroni zysk zamiast pompować sam obrót.

Zbij WIS, zautomatyzuj statusy i daj klientom samoobsługę. Prosty model supportu dla małych sklepów – z KPI i integracjami.

Praktyczny hub - jak wybrać platformę, policzyć TCO, zaplanować migrację i architekturę (monolit, pół-headless, headless).

Jak ustawić płatności, checkout i dostawy w PL/UE: BLIK, P24, punkty odbioru, etykiety, zwroty, Allegro/eBay. Szybkie wygrane dla CR.

Dowiedz się, jak zoptymalizować sklep internetowy pod kątem SEO – technika, treści i linkowanie, które przekształcają ruch w sprzedaż.

Dowiedz się, czym są UX i UI w sklepie internetowym, jakie elementy wpływają na ścieżkę zakupową oraz jak mała i średnia firma może poprawić wygląd i użyteczność swojego sklepu
Sekcja e-commerce na Digital Vantage: dowiedz się jak uruchomić sklep, zoptymalizować operacje i skalować sprzedaż bez nadmiernych kosztów.